人类和大语言模型(LLM)在判断方式上的差别
一篇挺有意思的论文,专门讨论了人类和大语言模型(llm)在判断方式上的差别。
center">在判断方式上的差别")
论文原文:osf.io/preprints/psyarxiv/c5gh8_v1
论文指出,在 “怎么知道、怎么做判断” 这件事上,人和 LLM 其实有很大不同。虽然 LLM 给出的答案常常看起来和人类的判断很像,但这种 “像” 只是表面,背后的判断机制完全不是一回事。
回顾 AI 的发展,从最早依靠规则和推理的 “符号 AI”,到后来按关键词筛选信息的系统,再到现在这种大规模生成式的 Transformer 模型,LLM 其实并不是那种 “理解了再形成观点” 的存在。它更像是在庞大的语料库中学会了语言的规律,然后在上下文里 “补全” 下一句话。用稍微技术一点但也直观的说法,LLM 的工作方式更像是在一个高维的 “词语连接网络” 里,根据概率选出下一个词,而不是像人那样基于对世界的信念来做判断。
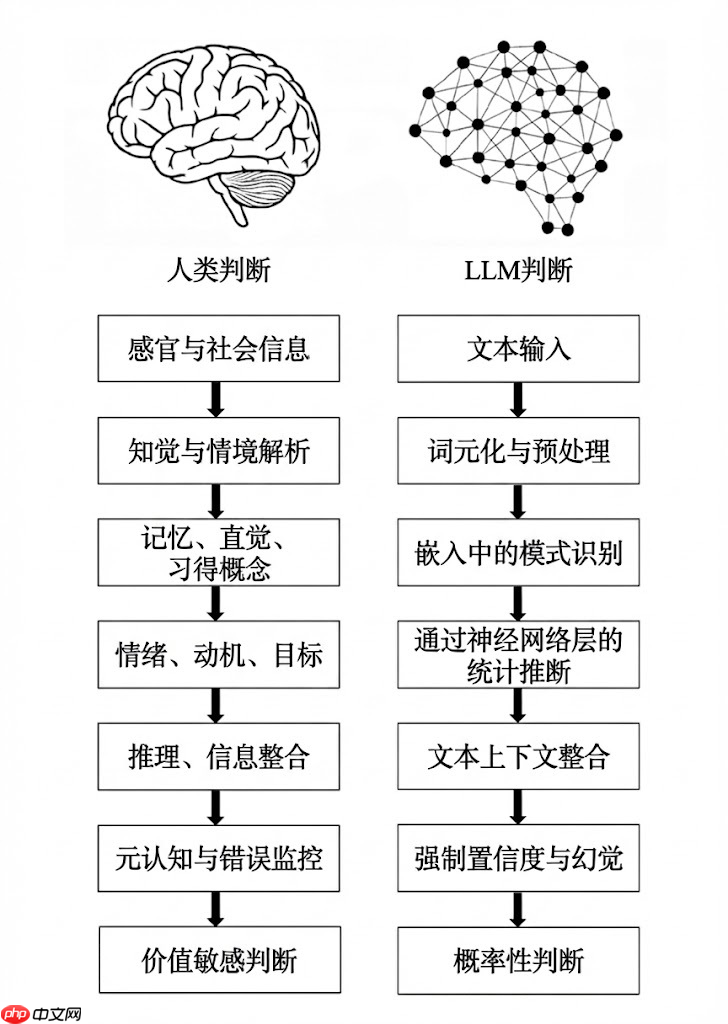
论文里,两位作者把人类和 LLM 的判断流程逐项对比,发现两者在七个关键环节上有着根本的区别:
1. 扎根断层:人类的判断是建立在感官、身体体验和社会经验之上的,而 LLM 只能靠文本,通过符号间接地 “重建” 意义。
2. 解析断层:人类理解场景是通过整合感知和概念,LLM 则是把文本分词、标记,得到的结构虽然方便处理,但语义其实很单薄。
3. 经验断层:人类靠情景记忆、直觉物理、心理和习得概念来判断,LLM 只能依赖嵌入(embeddings)里编码的统计关联。
4. 动机断层:人类受情绪、目标、价值观和进化动机影响,LLM 则没有内在偏好、目标或情感。
5. 因果断层:人类善于用因果模型、反事实推理来思考,LLM 不会主动构建因果解释,而是倾向于用表层的相关性来 “拼接” 答案。
6. 元认知断层:人类可以发现自己的不确定、修正错误,甚至暂停判断,LLM 没有元认知,必须不断输出内容,这也是 “幻觉” 难以避免的根本原因之一。
7. 价值断层:人类的判断会反映身份认同、道德和现实利害关系,LLM 只是在预测下一个词,没有真正的价值判断或责任感。
作者还提到,尽管有这些断层,大家还是很容易被 LLM 的流畅和自信所 “说服”,从而产生过度信任。这背后其实是一种 “可信度偏差”,也就是用漂亮的语言包装出来的东西看起来就更可信。
他们把这种现象称为 Epistemia(一种认识幻象或语言性认知错觉):我们经常会被语言的流畅性误导,以为自己已经 “知道了”,但其实本质上并没有真正理解。
针对 Epistemia,论文还提出了三种应对策略:认识性评估(epistemic evaluation)、认识性治理(epistemic governance)和认识性素养(epistemic literacy)。
来源:https://weibo.com/2192828333/QjQJM4J22
源码地址:点击下载
<< 上一篇
网友留言(0 条)